

[COMPTE-RENDU] Présentation de Louise Frion sur les communs numériques
23 juin 2023
[ESSAI D’ÉTUDIANT] À l’ère des géants de la tech, Meta est-il sur une voie dangereuse ?
27 juin 2023
Cet article présente deux projets de recherche menés par deux groupes d’étudiants de la filière Numérique, Nouvelles Technologies et Politiques Publiques du Master Politiques Publiques et Master Affaires Européennes de l’Ecole d’Affaires Publiques, dans le cadre du cours intitulé « Décoder les biais de l’intelligence artificielle » dispensé par Jean-Philippe Cointet et Béatrice Mazoyer. Ce cours invite les étudiants à explorer les questions de discrimination dans l’IA et à mettre la main sur des données et du code pour enquêter sur une question de politique publique de leur choix.
Premier projet : Découvrir les biais algorithmiques dans les algorithmes d’appariement parents-enfants dans les familles d’accueil
Aux États-Unis, plus de 400.000 enfants sont placés dans des familles d’accueil, et plus de 200 000 enfants y entrent et en sortent chaque année. Afin d’optimiser leurs ressources limitées, certains services de protection de l’enfance ont commencé à expérimenter des outils algorithmiques pour aider les travailleurs sociaux à prendre des décisions, notamment pour prédire les risques de maltraitance, recommander des lieux de placement et apparier les enfants avec des parents d’accueil capables de répondre à leurs besoins spécifiques. Si certains outils ont été salués par les chercheurs pour leur amélioration des résultats pour les enfants et la réduction des coûts, d’autres analyses sont sceptiques quant à la partialité, la difficulté d’explication ou l’opacité de ces outils. Dans notre rapport, notre groupe a cherché à découvrir si le traitement injuste des enfants issus de minorités était perpétué ou systématisé par les algorithmes de placement basés sur l’IA.
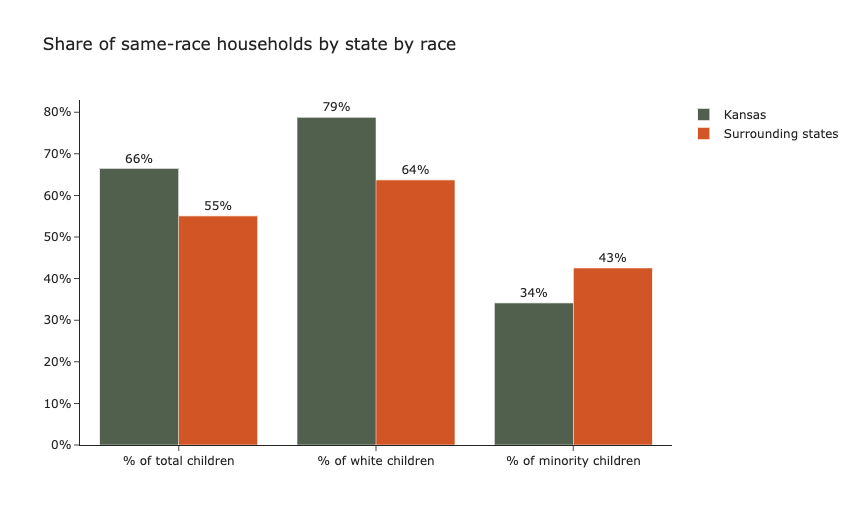
Les recherches préliminaires suggèrent que le placement des enfants dans des ménages de même race a un effet positif significatif sur le bien-être à long terme des enfants. Toutefois, le traitement inéquitable des enfants issus de minorités dans les algorithmes de placement peut menacer le bien-être de ce groupe particulièrement vulnérable. Pour vérifier si c’est le cas, notre projet a examiné si les enfants issus de minorités ont autant de chances d’être placés dans des ménages de même race que les enfants blancs. Pour l’analyse, nous avons utilisé les données de l’Adoption and Foster Care Analysis and Reporting System 2015 (AFCARS), un ensemble de données complet et détaillé compilé par le Children’s Bureau (CB) au sein de l’Administration for Children and Families (ACF) aux États-Unis. Nous avons exploité les données démographiques raciales pour examiner les placements en famille d’accueil au Kansas, l’un des premiers États américains à avoir adopté l’appariement basé sur l’IA, en le comparant à ses États voisins, le Nebraska et le Colorado, qui n’utilisaient pas de tels outils en 2015. Cette décision a été prise pour éliminer autant que possible la variabilité des caractéristiques des différents États. En utilisant cette méthodologie, nous avons exploré les questions de recherche suivantes :
- Existe-t-il une surreprésentation raciale parmi les familles d’accueil ?
- L’AFCARS est-il suffisamment représentatif pour être utilisé comme ensemble de données de formation ?
- Les États qui utilisent des modèles de recommandation de placement ou des modèles d’appariement enfant-parent d’accueil sont-ils plus susceptibles de prendre en compte le bien-être des enfants en les plaçant dans des ménages de même race ?
Lorsque l’on examine la composition démographique des placements en famille d’accueil dans son ensemble, il apparaît que les enfants placés au Kansas ont 11 points de pourcentage de plus que dans les États voisins pour être placés dans des ménages de même race. Cependant, l’analyse des sous-groupes a révélé un résultat plus déroutant : les enfants en famille d’accueil issus de minorités au Kansas ont 8 points de pourcentage de moins de chances d’être placés dans des ménages de même race, tandis que les enfants en famille d’accueil blancs au Kansas ont significativement plus de chances d’être placés dans des ménages de même race. D’une part, il est rassurant de constater qu’un système utilisant l’appariement algorithmique est significativement plus susceptible de placer les enfants dans des ménages de même race dans l’ensemble. D’autre part, un système utilisant l’appariement algorithmique diminue considérablement la probabilité qu’un enfant en famille d’accueil appartenant à une minorité soit placé dans un foyer qui génère des résultats positifs à long terme. Les enfants en famille d’accueil issus de minorités étant une sous-population particulièrement vulnérable, les résultats suggèrent que l’appariement algorithmique peut désavantager de manière disproportionnée un groupe qui est déjà systématiquement désavantagé.
Cette étude a pour but d’éclairer les recherches futures sur les outils de prise de décision impartiale utilisés dans les procédures de placement en famille d’accueil, qui constitueront la principale forme d’assistance pour les autorités qui s’efforcent de protéger les enfants vulnérables et de leur offrir les meilleurs résultats possibles. Ce faisant, des algorithmes d’appariement plus avancés peuvent prévenir les préjugés sous-jacents qui favorisent les enfants blancs au détriment des enfants issus de minorités.
Auteurs : Stavroula Chousou, Yasmine El-Ghazi, Ludovica Pavoni, Lea Roubinet et Morgan Williams
Deuxième projet : Les biais existant derrière les algorithmes de génération d’images
De l’art de l’IA aux « deep fakes », les algorithmes générateurs d’images émergent dans des discussions qui touchent à la culture, à la philosophie et à la politique.
Un exemple fréquent – également repris dans notre article – est Stable Diffusion, lancé en 2022 par Stability AI. Suivant les traces de DALL-E d’Open AI, il s’agit d’un modèle capable de générer des images à partir de descriptions textuelles. Il fonctionne grâce à ce que l’on appelle les GAN (Generative Adversarial Networks), un modèle génératif qui s’appuie sur l’estimation contrastive du bruit pour permettre à un système de distinguer les données du bruit. Plus précisément, Stable Diffusion est entraîné sur un total de 2,3 milliards de paires image-texte et utilise un modèle de diffusion latente (LDM), une alternative moins coûteuse en termes de calcul que les méthodes employées dans DALL-E, mais qui permet de conserver la qualité et la flexibilité. Cela correspond tout à fait à l’approche de Stability AI en matière de développement de l’IA qui, contrairement à celle d’OpenAI, est open source. Cela signifie que les utilisateurs peuvent accéder au code, aux poids, créer des forks et, en somme, utiliser Stable Diffusion avec peu de mesures de sécurité obligatoires. C’est pour cette raison que nous avons décidé de tester la façon dont StableDiffusion pourrait façonner une manière différente de s’engager dans les biais algorithmiques. En effet, les questions de partialité et d’équité, le plus souvent illustrées par des préjugés fondés sur la race ou le sexe, font partie intégrante du débat sur l’IA générative.
Notre recherche s’est penchée sur les préjugés de Stable Diffusion en explorant des préjugés qui n’ont pas fait l’objet d’études aussi approfondies dans la littérature académique : la religion et la culture. Comment le système de génération d’images de Stable Diffusion traiterait-il la religion ?
Pour le vérifier, nous avons effectué une analyse qualitative basée sur huit religions ou catégories de religions – christianisme, islam, hindouisme, bouddhisme, sikhisme, judaïsme, shintoïsme et athéisme – avec l’invite « Une photo du visage de _ » suivie d’un terme neutre désignant un adepte de chacune des religions sélectionnées. Tout d’abord, nous avons constaté que les images générées par Stable Diffusion affichent un large éventail de stéréotypes et ont particulièrement tendance à les amplifier. Par exemple, la corrélation entre la masculinité et la religion est prépondérante dans les résultats de l’IA – les seules caractéristiques féminines générées se trouvant dans les échantillons représentant l’islam et l’hindouisme. À cet égard, nous avons également constaté que les images surestiment le symbolisme religieux. Les hindous (hommes et femmes) portent des bindis et/ou d’autres bijoux décoratifs sur le front, tous les sikhs portent des turbans et tous les bouddhistes représentés humainement ressemblent à des moines (« bouddhistes représentés humainement » pour faire la distinction avec les statues bouddhistes que l’IA de stabilité a également générées). Comme nous l’affirmons, le modèle s’appuie sur des représentations « non ambiguës » de la religion, même sans y être invité. Nous supposons que cela peut amplifier les impressions rétrogrades et sous-développées de ces religions.
Sur une note plus positive, les images n’affichent pas les stéréotypes négatifs courants à l’encontre de certaines religions – ce qui est particulièrement clair dans le cas des musulmans, qui sont souvent représentés dans la couverture médiatique des événements terroristes, ce qui aurait pu établir un lien entre l’islam et les comportements violents. En termes d’ethnicité, la plupart des religions sont représentées par leur origine culturelle majoritaire.
Nous avons ensuite examiné les « préjugés complexes », en testant la manière dont le modèle associait certains groupes religieux à un ensemble particulier d’antécédents, d’attitudes ou de circonstances. Pour ce faire, nous avons modifié l’invite initiale en spécifiant la période ou le sexe. Cela s’est avéré évident dans le cas du judaïsme, où les images générées ressemblaient nettement à des portraits photographiques monochromes du début du 20e siècle, sans couleurs et avec des modes et des poses dépassées. Cela contribue à l' »historicisation » de la religion, qui a toutefois été rejetée par diverses organisations juives comme étant réductrice. D’autres préjugés de ce type, qui s’appuient sur des « hypothèses et des relations de pouvoir pernicieuses », sont analysés plus en profondeur dans le document.


Dans l’ensemble, nos conclusions mettent en évidence un biais occidental qui nuit à la représentation des minorités religieuses en Occident, notamment par des représentations erronées et des performances disproportionnées. Si l’accent mis par Stability AI sur la transparence est d’une importance cruciale, l’impartialité des données de base au niveau du prétraitement doit devenir une préoccupation majeure. Cela signifie qu’il faut élaborer des « déclarations de données » et des « fiches de données » pour accroître la transparence des bases de données et de leur architecture afin de faciliter l’étude des biais et d’y remédier. Une telle pratique peut permettre au conservateur des données de résumer et de motiver les caractéristiques de l’ensemble de données et les méthodes de création. Cela s’inscrirait également dans l’approche plus large de l’IA de la stabilité en matière d’IA. En fait, le fait d’inscrire l’ouverture comme valeur fondamentale de Stable Diffusion a des conséquences importantes sur la manière dont Stability AI considère les biais : l’idée est que, même si Stable Diffusion peut effectivement perpétuer les biais, à long terme, l’approche communautaire produira un bénéfice net. Les déclarations de données seraient un bon moyen de permettre une plus grande coopération au sein de cette communauté.
Auteurs : Barbora Bromová, Giovanni Maggi, Christoph Mautner Markhof, Riccardo Rapparini et Laura Zurdo